
Power Automate
Automatisez vos tâches répétitives, orchestrez vos processus métier, répétez indéfiniment vos actions de bureau.
Organizer:
- Organisé par
-
Import dataverse
Import dataverse
Bien le bonjour,
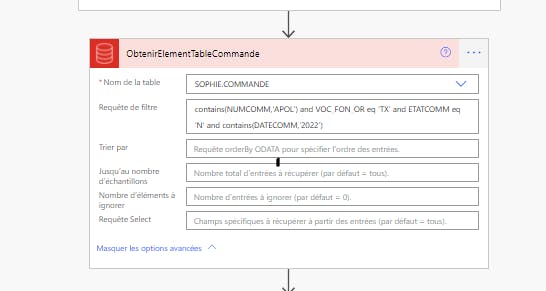
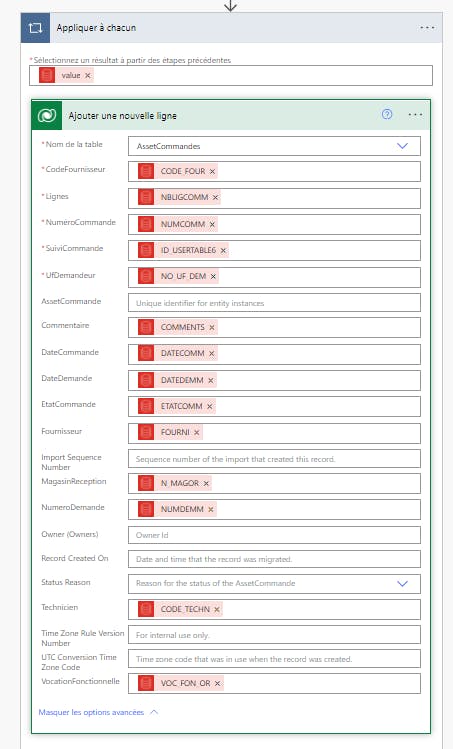
j’ai un flux automatisé qui va chercher des données dans une base Oracle ( environ 5k lignes),ensuite j’importe le tout dans un table data verse for teams, ce flux s’exécute 1 fois par jour.
L’export depuis Oracle s’exécute en 5secondes.
Je rencontre une problématique avec l’import, celui-ci prend plus de 10 minutes et s’arrête à ce moment avec un message d’erreur (délais d’exécution ). Je suis à environ 2000 lignes au moment où stop le flux.
Edit : J’ai relancé le flux, finalement il s’est exécuté sans problèmes mais en 17 minutes pour 2060 lignes. Savez s’il est possible d’accélérer le traitement ? Est ce que j’ai mal configuré mon flux ?
Merci d’avance. 😉
PostID=Q4iQQpoGn33SuI3
Connectez-vous pour répondre.