
DavidZed
MembreRéponses céées sur le Forum
-

Bonjour Jonathan ,
Essaies Connection.Connected()
Cela te retournera true si le device est connecté à un réseau (par contre ça ne prend pas en compte si la connexion dispose d’un accès internet ou pas)
CommentID=kKQlYfoghKboh5T, PostID=shNtVWJr4SzeamT
-
Bonjour Gerald ,
Le résultat Distinct() est exclusivement une table d’une colonne qui contient des valeurs uniques.
Je pense que la formule qui répondra le mieux à ce que tu veux faire est un GroupBy() : https://docs.microsoft.com/fr-fr/power-platform/power-fx/reference/function-groupby
La syntaxe devrait ressembler à :
GroupBy(Filter(['Ta source'];[Tes conditions]);[Colonne principale];[Nom de la colonne groupée])CommentID=wyxfqMp81m7VFCj, PostID=cx4MXRykjiVJGjX
-
Hello,
A première vue, je dirai que le trigger du flux d’approbation ne détecte pas le fichier déplacé comme un nouveau fichier mais peut être simplement comme une modification d’un fichier existant.
option 1 : Si tu utilises l’action “déplacer le fichier” à la suite d’un refus, remplace la par Copier un fichier + supprimer un fichier (celui resté dans workflow)
option 2, gérer le statut de validation avec une colonne type choice, et paramétrer le trigger avec pour condition :
Si un fichier est créé ou modifié, et si statut de validation = Soumis à validationoption 3: faire en sorte que l’utilisateur qui revoit son document, enregistre une copie dans workflow pour le forcer à créer un nouveau fichier (dossier documents supprimés à mettre en lecture seule)
CommentID=D3Mqq74nPvqwqRx, PostID=Zd3X2WheshhD9iN
-
il faut le mettre en valeur par défaut sur la colonne
SubCommentID=aHIUoctRx310FUv, CommentID=D3Mqq74nPvqwqRx, PostID=Zd3X2WheshhD9iN
-
-
Hello R3dKap ,
1: Oui, ça se passe au niveau du mappage, il faut cocher la case :

Par contre cela rend obligatoire la création d’une clé dans ta table dataverse.
2: toujours en se basant sur le principe que tu crées une clé pour ta table, ce qui va se passer quand ton dataflow va tourner :
-
s’il ne trouve pas la clé, il crée un record
-
s’il la trouve, il met à jour
-
Si tu as coché l’option citée plus haut et si un record de la table n’est pas dans la sortie de requête, il est supprimé de la table
3: là encore, il faudra marquer une colonne comme key dans la table destination du lookup que tu retrouveras dans ton volet de mappage

Ici c’est un lookup vers la table Accounts, dont la colonne COD_PRESTA a été marquée comme clé:

CommentID=GnCCh3ST3qmolUM, PostID=ZCTKnIyS9jBkZgF
-
-
Hello,
C’est possible via l’action “Send http request to Sarepoint” qui exploite l’API sharpeoint REST :
C’est un peu hard au début mais cela permet de faire presque tout ce que tu veux sur SP via Power Automate 👍 Je ne l’ai jamais utilisé sur cette fonctionnalité, mais je sais que c’est possible 😄
Si tu veux une solution plus simple, l’idéal serait peut-être de créer un dossier avec les “documents approuvés”, accessible en lecture seule aux utilisateurs
Et au niveau de ton flow, quand un document est validé, tu le déplaces dans ce dossierCommentID=mMyhApm6L1tZgv8, PostID=nFkiiY0lvB7OR3x
-
Hello,
Essaies avec Sort() et le display name de ta colonne, mais si ça ne marche pas c’est que ce n’est pas supporté 🙁
CommentID=QsCdTwdXtanLgyl, PostID=3wvLDkOc4GvzYCo
-
DavidZed
Membre9 septembre 2022 à 9h55 en réponse à: Récupérer le lien d'un document dans une demande d'approbation.Encore plus simple, tu peux avoir le lien directement en utilisant le trigger :
“When a file is created (properties only)”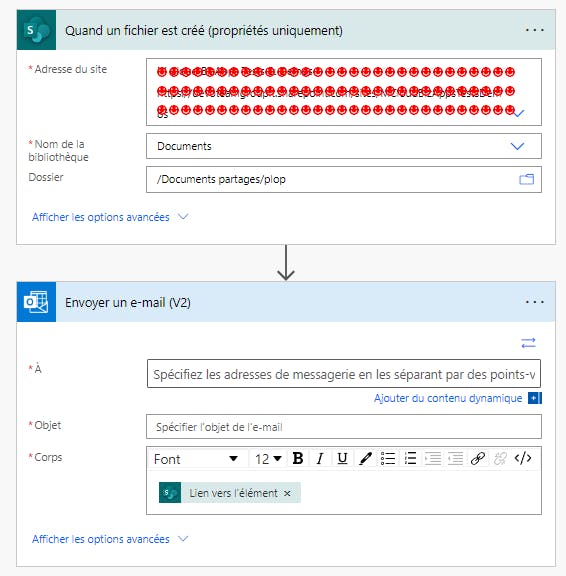
CommentID=FlbENsfHT4voffn, PostID=gBeTJGtn3kERD6a
-
DavidZed
Membre9 septembre 2022 à 8h16 en réponse à: Récupérer le lien d'un document dans une demande d'approbation.Hello Jfk2lax ,
Il te faut ajouter l’action “obtenir les propriétés du fichier” et tu auras l’url dans le paramètre “lien vers le fichier”
CommentID=Dh1cejTJUMnkOob, PostID=gBeTJGtn3kERD6a
-
-
Voici ce que ça devrait donner :
CommentID=zH6t4VFngtKj77K, PostID=K4esEkhCOOWqxwx
-
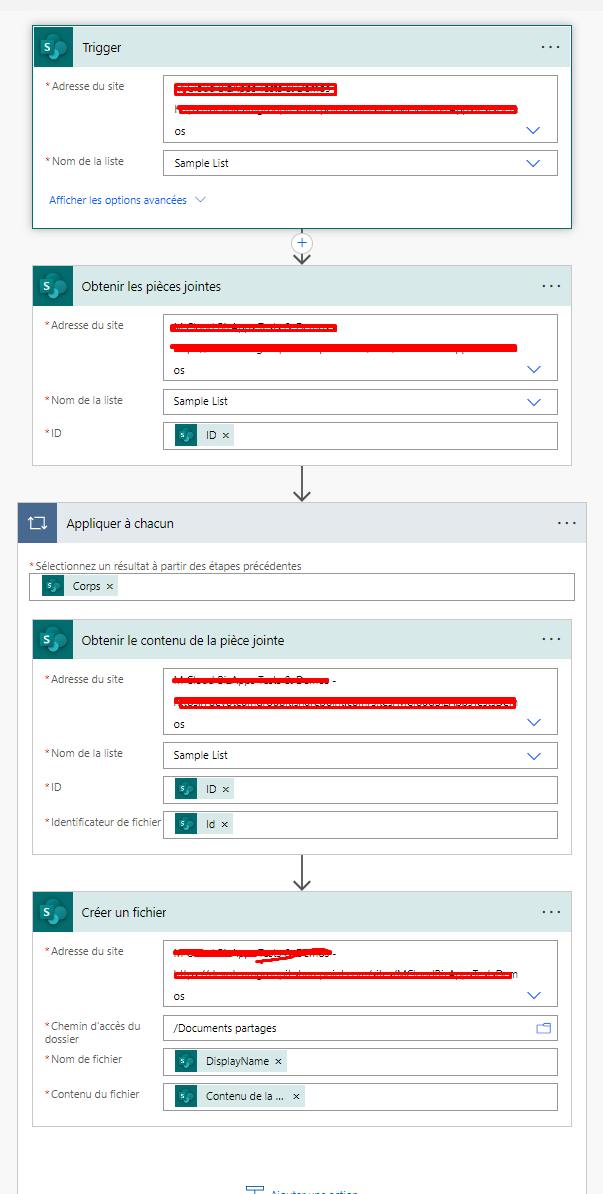
Bonjour Delphine,
Voici les actions SharePoint à utiliser, dans l’ordre :
-
Quand un item est modifié
-
Obtenir les pièces jointes
-
Obtenir le contenu de la pièce jointe (cela va te mettre un appliquer à chacun)
-
Créer un fichier
C’est assez linéaire, dans la plupart des actions, les données sont à récupérer dans l’action précédente.
CommentID=peYV8zjW2SFH3kI, PostID=K4esEkhCOOWqxwx
-
-
Quand tu dis “qui ont pas le même nom”, tu parles des noms des colonnes ? Si c’est ça, ce n’est pas un problème, puisqu’en sortie de dataflow, tu vas devoir mapper ta requête sur les colonnes de ta table de destination, peu importe le nom qu’elles ont à l’entrée. Il faut juste que tu fasse attention à bien mapper correctement la colonne de sortie de requête avec la bonne colonne de ta table dataverse.
Au pire, tu peux même renommer les colonnes pendant la transformation de données pour qu’elles correspondent à ta table et faire ensuite un “mappage auto”
Par contre si tu n’as pas une valeur commune entre les deux tables, il te sera impossible d’identifier si un client est présent dans les deux tables, donc tu risques d’avoir des doublons
CommentID=2DNMGZQxOsUT3Cs, PostID=aXBeu3Y2FhJTrvN
-
Une fois créé, on peut rattacher un dataflow existant à une solution : Add existing > Automation > Dataflow
Mais je t’avouerai que je n’ai pas poussé plus loin l’utilisation de la fonctionnalité, je gère généralement mes dataflows hors solution.
Pour dupliquer rapidement un dataflow sur un autre environnement, je viens copier l’ensemble de la requête en mode advanced editor :
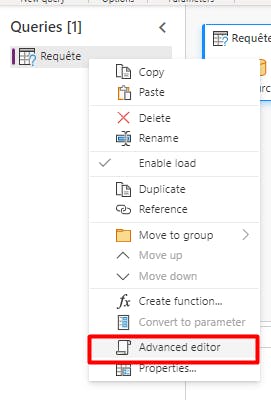
Et je la colle dans une nouvelle requête vierge sur l’env de destination
Tu peux procéder ainsi pour changer tes sources de données en fonction de la situation / de l’étape de ton dev
SubCommentID=bV1FN6OP3YkMTm8, CommentID=cu56wqw4V3l4ZX4, PostID=ZCTKnIyS9jBkZgF
-
Si c’est un impératif de faire une purge & import, c’est faisable via un power automate qui vide la table suivi de l’action “Refresh a dataflow”
Le soucis c’est sur de gros volumes de données, tu auras potentiellement de la donnée inaccessible entre le début du remove all et la fin du refresh du dataflow.
Alors que via la méthode décrite en 1, une fois le dataflow terminé, chaque ligne de la table sera soit une nouvelle ligne, soit une ligne mise à jour intégralement, le reste aura été supprimé. Avec l’avantage que ta donnée est 100% disponible durant toute l’exécution pour le même résultat au final.
SubCommentID=0D3MROnodQ80UAo, CommentID=MhuS0TU3YcLzRIt, PostID=ZCTKnIyS9jBkZgF