
DavidZed
MembreRéponses céées sur le Forum
-

DavidZed
Membre6 octobre 2022 à 19h16 en réponse à: Restreindre la possibilité à la fonction importer une solution uniquementSi la solution utilise Dataverse, ajouter les droits nécessaire risquerait d’être long et fastidieux.
Je privilégierai à la place, de créer un rôle de sécurité custom en partant du rôle System customizer comme base, et en enlevant certains droits : la suppression de solutions, applications et tables par exemple. Ce sera plus rapide.
CommentID=9wdd0VHwg5TIYr9, PostID=fZBcCy7J2gJxKhI
-
Hello Dav ,
Pour moi, il y a deux problèmes : la fonction Search() ne fonctionne qu’avec une chaîne de caractères, et tu dois filtrer sur des données qui sont dans des relations multiple à multiple :
Une personne peut être associée à plusieurs projets et un projet peut compter plusieurs personnes
Pour le search, l’idéal est de le remplacer par un filter() et de mettre ta liste de choix dans un combobox par exemple :
Filter('Table Projets PwApps';ComboBox1.Selected.Value in Service; TextSearchBox1.Text in ville || TextSearchBox1.Text in projet || TextSearchBox1.Text in Nom)Si tu as des choix multiples dans ta colonne, tant que tu recherches sur un critère, c’est assez simple, comme l’exemple au dessus. Si tu dois filtrer sur une colonne à choix unique mais sur plusieurs critères, là encore ça reste simple. Par contre si tu dois rechercher plusieurs critères dans une colonne à choix multiple, là ça devient assez complexe en canvas, et généralement on évite car ça ne donne pas spécialement un filtrage utile ou pertinent.
CommentID=gPALaNwLZopXYVh, PostID=8txKIBj8zm77kLe
-
Hello Marine
La valeur que tu vas récupérer dans un Param() va être de type texte, l’Id d’un item Sharepoint est de type nombre entier.
Tu dois pouvoir convertir ton texte en valeur numérique avec un Value(), ce qui donnerait :
ID= Value(Param("ficheId"))L’inverse fonctionnera certainement aussi, en convertissant l’ID numérique en text string :
Text(ID)=Param("ficheId")CommentID=z60mLHw3G9JUtbk, PostID=395oGbalgO3tNvn
-
Le message d’erreur n’en dit pas vraiment long, pour avoir une vision plus claire sur ce qui cloche avec cette variable, il faut aller dans le menu “view” puis “variables” :

ensuite, sélectionner l’écran et la variable de contexte et voir s’il y a une erreur dans le datatype de la variable
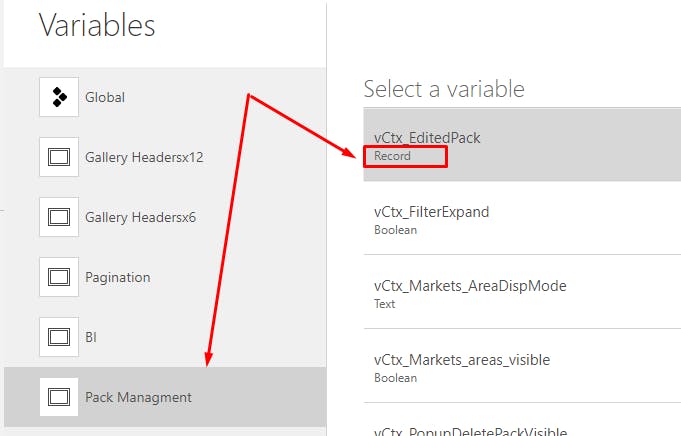
S’il y a une erreur, il faudra cliquer sur la variable et s’intéresser à l’onglet définitions :
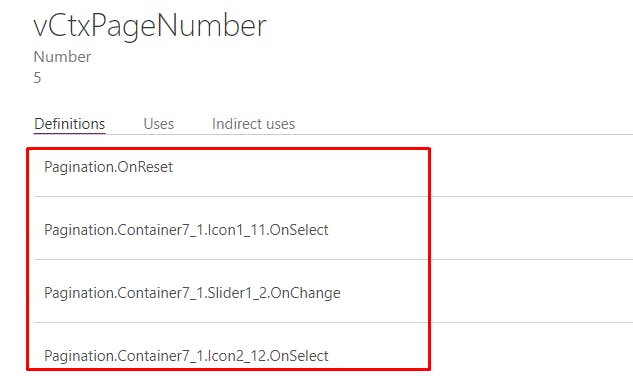
C’est dans cet onglet que tu vas retrouver tous les endroits (objets & actions) où ta variable est définie, il faudra passer en revue chaque ligne de cette table pour voir si tu n’as pas une définition (updatecontext) qui défini un schéma incompatible : source de donnée différente, colonne ajoutée ou renommée…
Pour identifier plus rapidement le contrôle fautif, tu peux mettre toute la formule en commentaire dans tous les contrôles, puis la recharger, contrôle par contrôle en supprimant le //, jusqu’à ce que l’erreur soit à nouveau visible.
SubCommentID=Vxk8o9KE4wNyRMh, CommentID=z60mLHw3G9JUtbk, PostID=395oGbalgO3tNvn
-
-
DavidZed
Membre4 octobre 2022 à 15h07 en réponse à: envoyer un courriel en fonction de l'état d'une colonneHello Jfk2lax
Il faut que tu sois vigilant sur ce genre de flux, car celui-ci peut vite consommer de la ressource inutilement et avoir des déclenchements indésirés.
-
En tout premier lieu, les éléments essentiels à vérifier :
-
Ton déclencheur pointe bien vers la bonne liste ?
-
Ton flux est-il activé ?
-
La valeur dynamique dans ta condition est-elle bien la bonne ? (si c’est un choice ou un lookup, il faut prendre Statut Value pour le comparer au texte “Terminée”, sinon tu vas récupérer un record avec Id et Value)
Ensuite, il vaudra mieux privilégier une condition de déclenchement dans les paramètres avancés de ton trigger sharepoint plutôt qu’une condition
Ton flux ne va se déclencher que si l’item est modifié et le statut est “Terminé”
Si tu utilises une condition comme dans ton exemple, ton flux va se déclencher pour toutes les modifications de l’item, arriver à la condition et continuer si le statut est “Terminé”Exemple ici avec un champ booléen (le nom de la colonne est YesNo ):
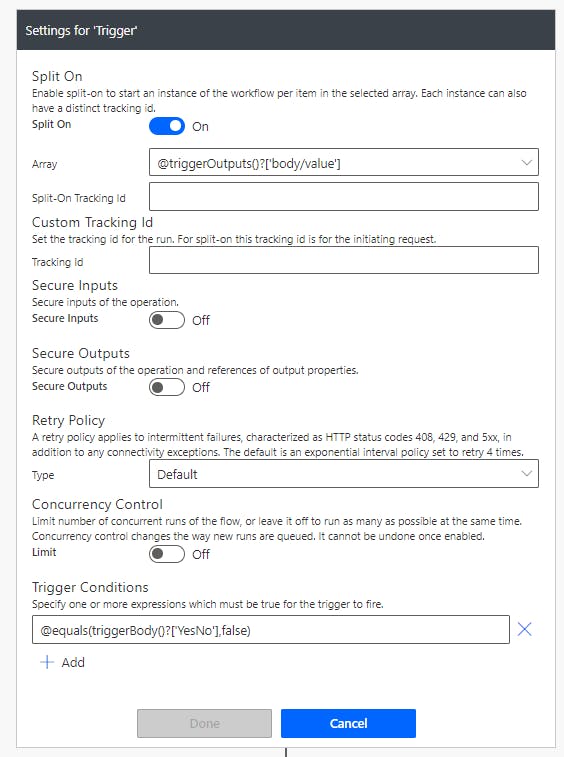
CommentID=mmKXTVT46nFvEFO, PostID=t5mTp7NaTh33lDi
-
-
A savoir que sans cela il y a une notif d’erreur de base quand le user n’a pas l’autorisation pour une action, mais dans un langage un peu barbare pour l’utilisateur 🙂
CommentID=Ye8iWAkI9wbXuei, PostID=iEU7NEQUijRGGk0
-
Hello R3dKap ,
Dans cette situation, il m’arrive de personnaliser le message d’erreur avec la fonction IfError, exemple :
IfError(Remove('Table Source Dataverse',ThisItem),Notify("Message d'erreur custom",NotificationType.Warning),Remove('Table Source Dataverse',ThisItem))A noter que tu peux aussi récupérer des éléments de l’erreur avec FirstError / AllErrors / ErrorResult au sein du IfError
CommentID=pvbSUHNWUzQY5OB, PostID=iEU7NEQUijRGGk0
-
Pour l’affichage, celui du haut est la nouvelle version qui est disponible depuis une semaine ou deux, en bas c’est l’ancien.
S’il y a des disparités entre utilisateurs, il faut que ces derniers vident le cache de leur navigateur
CommentID=0nrOxZAS87tZF52, PostID=LXSRpj0XJlgvXmH
-
Hello,
Tu as trouvé la solution 😉
A savoir, l’environnement n’est pas toujours visible tout de suite pour l’utilisateur qui vient d’être ajouté au groupe. Il vaut mieux lui fournir un lien direct vers l’environnement.
CommentID=GDNura6F2mndo0o, PostID=LXSRpj0XJlgvXmH
-
Hello Sebastien Brandeis ,
Pour ce qui est du nommage des objets dans l’app studio, par contre il peut être interessant de normer le nommage des variables selon leur type : contexte, globale, collection etc..
Pour les objets : toujours conserver le nom de base : button…. , DropDown…. Label…. et mettre le nommage en suffixe en priorité, cela permet de retrouver facilement un contrôle par son type avec la fonction search. Ne mettre un préfixe que pour tagger des objets qui doivent faire l’objet d’une catégorisation indépendante. Par exemple, je met un DEV_ sur tous les contrôles masqués que je ne souhaite pas afficher dans l’appli (contrôles hors champ) cela me permet de modifier rapidement certains paramètres pour que le contrôle soit réellement inaccessible : taquets de tabulation…
CommentID=4x04spxQ7DHqiHR, PostID=zjm4yBNRF7QrTcA
-
Hello Sebastien Brandeis ,
Pour Dataverse, mettre en place des règles de nommage sur le ‘shema name’ présente assez peu d’intérêt, voire peut se révéler handicapant dans certains cas.
Exemple quand tu te retrouves à devoir manipuler les colonnes dans l’pp studio avec des showcolumns / dropcolumns etc… il est très pratique de pouvoir déduire le shema name facilement (Préfixe de l’éditeur + display Name sans les espaces et caractères spéciaux)
CommentID=4b3HTOkHD9cDrN2, PostID=Bcjo0E7y9lwWty4
-
Hello Eric ,
J’ai fait quelques essais pour ton soucis, il me semblait que l’on pouvait faire ce type de recherche en utilisant des “*” exemple test*.* mais cela génère une erreur.
Il y a possibilité de récupérer un liste de fichiers dans le dossier pour ensuite la filtrer et aller récupérer le bon fichier. Mais je me demandais s’il ne serait pas plus simple de modifier le nom de ton fichier au sein même du ‘Appliquer à chacun’ à l’aide d’une variable, le cheminement devrait ressembler à ceci :
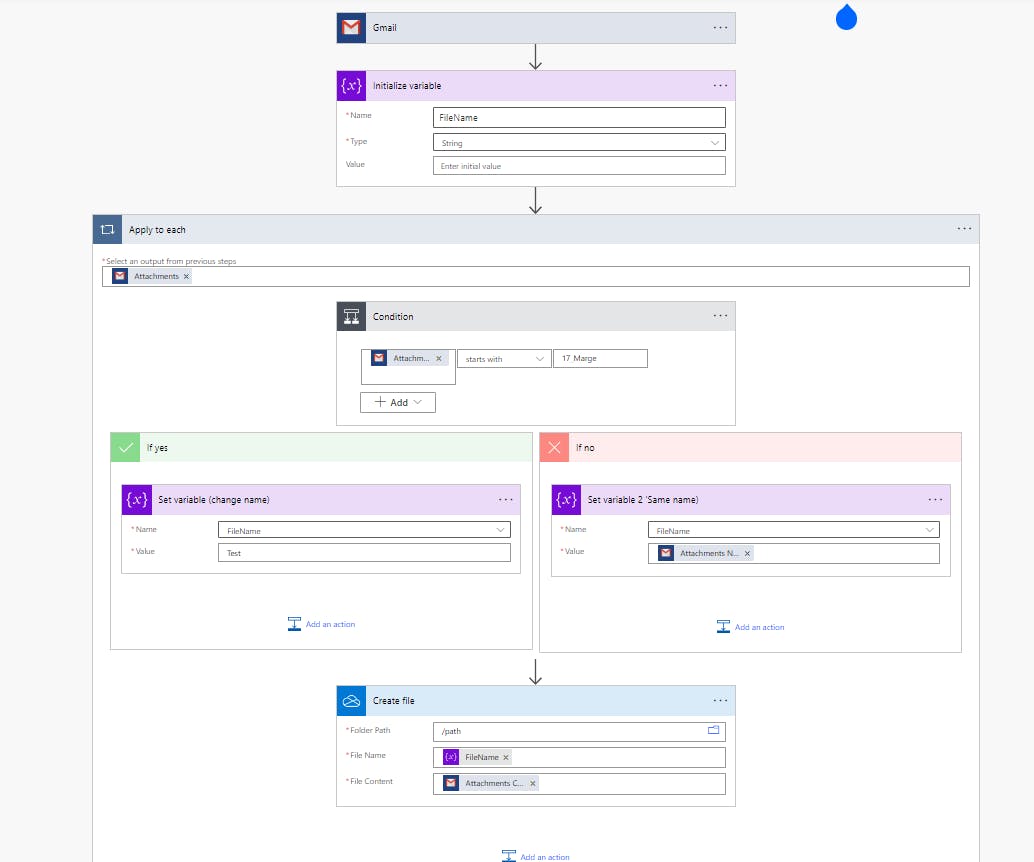
CommentID=LynIB7glXJIAf2J, PostID=W6226LiFDe9ZFJ4
-
Il y a deux ‘appliquer à chacun’ imbriqués, cela vient du fait que tu as mis une mauvaise valeur dynamique dans la variable en encadré, il faut mettre la valeur attachment name (la même que dans la condition)

SubCommentID=weIBjA3mO0eaPLV, CommentID=LynIB7glXJIAf2J, PostID=W6226LiFDe9ZFJ4
-
-
Hello FRED b.
Tes utilisateurs “Guests” auront besoin du même niveau de licence que tes utilisateurs internes, c’est à dire :
Si ton application utilise sharepoint et des connecteurs standard, il aura besoin d’une licence office 365, il peut par contre autoriser certains connecteurs en identifiant sa licence externe s’il en a une.
Si ton application utilise Dataverse ou des connecteurs premium, il aura besoin de consommer une license Power Apps per app.
Si ton application utilise les deux : ex Dataverse et un connecteur outlook (standard), il lui faudra les deux.
A noter que l’accès invité n’est viable que si tu as une minorité de user externes, autrement, il est beaucoup plus intéressant de passer par un portal / power page.
CommentID=6gPsj4PXO33dZia, PostID=HE3CR0jGusmlk29
-
Hello Romain ,
Via power automate, c’est assez simple, le flux ressemblerait à ceci :
-
Quand un fichier est créé ou modifié
-
Condition sur une métadonnée (colonne, voir plus bas)
-
-
Lister les membres d’un groupe M365
-
Nom du groupe avec tous les destinataires
-
-
Appliquer à chacun
-
Poster une carte adaptative dans un chat ou un canal
-
Post as flow bot / post in Chat with flow bot / Recipient userId
-
-
Les points à affiner :
Mettre une métadonnée au fichier de la news qui servira de condition, pour lancer la diffusion, car sinon tu risques d’avoir des soucis si tu crées une news par erreur, un brouillon etc…
L’idéal est de faire un groupe qui n’inclue que les personnes physiques et d’en exclure les comptes non nominatifs, le copieur du 3eme etc…
Sur le “apply for each”, il faut activer le mode ‘concurrent’
dans les settings avancésC’est une solution qui peut convenir pour une petite structure, mais si c’est pour un grand groupe (20k users et+) , il sera préférable de trouver une solution un peu plus élégante. Je laisse le soin aux spécialistes de SP d’affiner 🙂
CommentID=LflYedJgr6tavZx, PostID=iZckqMLfiyv9vTr
-